算法总复习,包含分治,图算法,动态规划,线性规划,P与NP,规约等重点知识的总结。
Divide and Conquer
Master theorem:
for some constants (a>0) , (b>1) ,and (d ≥0) , then
d代表非递归部分(即每次递归调用之外的操作)的时间复杂度的指数。
证明:分析递归树的总工作量
FFT
Graph Algorithms
DFS
1 | EXPLORE(G, v): |
running time:O(|V|+|E|)
SCC (强连通分量)
1 | Input: 有向图 G = (V, E) |
running time:O(|V|+|E|)
Dijkstra
1 | **Input**: 图 G, 边权 ℓ, 起点 s |
Bellman-Ford
1 | **Input**: 图 G, 边权 ℓ, 起点 s(无负环) |
running time:O(|V| * |E|)
DAG 最短路
拓扑顺序是指在有向无环图(DAG)中,所有边 (u, v) 都满足 u 在 v 之前的线性序列。1
2
3
4
5
6
7
8
9
10
11
12Input: DAG G, 边权 ℓ, 起点 s
Output: 最短距离 dist[]
1. for each u ∈ V:
2. dist[u] = ∞; prev[u] = nil
3. dist[s] = 0
4. L = 拓扑排序(G) # 按线性序排列节点
5. for each u ∈ L (按序处理):
6. for each 边 (u, v) ∈ E:
7. if dist[v] > dist[u] + ℓ(u, v):
8. dist[v] = dist[u] + ℓ(u, v)
9. prev[v] = u
running time: O(|V| + |E|)
MST (最小生成树)
1 | Kruskal(G) |
切割性质:对于图G的任意切割(S, V-S),连接S和V-S的最小权重边必然在某个MST中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23并查集
# 初始化单元素集合
makeset(x):
1. π[x] = x # 父指针
2. rank[x] = 0 # 秩
# 查找根(带路径压缩)
find(x):
1. if x ≠ π[x]:
2. π[x] = find(π[x]) # 递归压缩路径
3. return π[x]
# 合并集合(按秩合并)
union(x,y):
1. rx = find(x), ry = find(y)
2. if rx == ry: return
3. if rank[rx] > rank[ry]:
4. π[ry] = rx
5. else:
6. π[rx] = ry
7. if rank[rx] == rank[ry]:
8. rank[ry]++
Dynamic Programming
动态规划(Dynamic Programming)
- 核心思想:将问题分解为重叠子问题,存储子问题解避免重复计算。
- 关键步骤:
- 定义子问题
- 建立递推关系(状态转移方程)
- 确定计算顺序(自底向上或记忆化搜索)
- 应用场景:
- 最长递增子序列 (LIS):以 j 结尾的 LIS 长度
- 编辑距离:字符串对齐的最小差异代价,
- 背包问题:
- 重复背包:
- 01 背包:
- 矩阵链乘法:最小化乘法次数,
- 旅行商问题 (TSP):C(S,j) 为通过集合 S 以 j 结尾的最短路径,复杂度 O(n^2 2^n)。
- 树上的独立集:最大独立集大小
LIS(最长递增子序列)
1 | Input: 序列 a[1..n] |
running time: O(n^2)
LCS(最长公共子序列)
1 | Input: 序列 a[1..n], b[1..m] |
running time: O(n*m)
01背包问题
1 | Input: 物品重量 w[1..n], 价值 v[1..n], 容量 W |
Linear Programming
MAX Flow
1 | FORD-FULKERSON(G, s, t): |
Ford-Fulkerson思想:
- 构建残差图:正向边剩余容量 = c_e - f_e,反向边容量 = f_e
- 迭代寻找增广路径:在残差图中用BFS/DFS找s→t路径
- 更新流量:增加路径上最小残差容量的流量
- 复杂度:O(|V|·|E|²)
Max Flow-Min Cut 定理:最大流等于最小割,即在流网络中,源点到汇点的最大流量等于将网络分割成两部分时,割边的最小容量。
二分图匹配可以通过归约到最大流算法解决,将二分图转化为流网络,源点连接到左侧节点,右侧节点连接到汇点,边的容量为1。
Simplex
Dual LP

P vs NP
P类问题:
- 存在多项式时间算法可以求解的决策问题
- 时间复杂度为 O(n^k),其中 k 是常数
NP类问题:
- 给定一个解,可以在多项式时间内验证其正确性的决策问题
- Nondeterministic Polynomial time
NP-Complete问题:
- 属于 NP 类的问题
- NP 类中的任何问题都可以在多项式时间内规约到它
- 如果任何一个 NP-Complete 问题有多项式时间算法,则 P = NP
NP-Complete
Search Problem: 给定实例 I 和解验证器 C(I,S)(多项式时间验证),寻找解 S
搜索问题等价于NP问题。
| 问题 | 描述 | 对比的 P 类问题 |
|---|---|---|
| 3SAT | 三变量子句的可满足性 | 2SAT(二变量子句) |
| TSP | 旅行商问题(最小代价环游) | 最小生成树 |
| LONGEST PATH | 图中最长简单路径 | 最短路径 |
| 3D MATCHING | 三集合匹配(男-女-宠物) | 二分图匹配 |
| KNAPSACK | 背包问题(整数权重/价值) | 单位权重背包(动态规划) |
| INDEPENDENT SET | 图中独立集(无相连顶点) | 树上的独立集 |
| ILP | 整数线性规划 | 线性规划(单纯形法) |
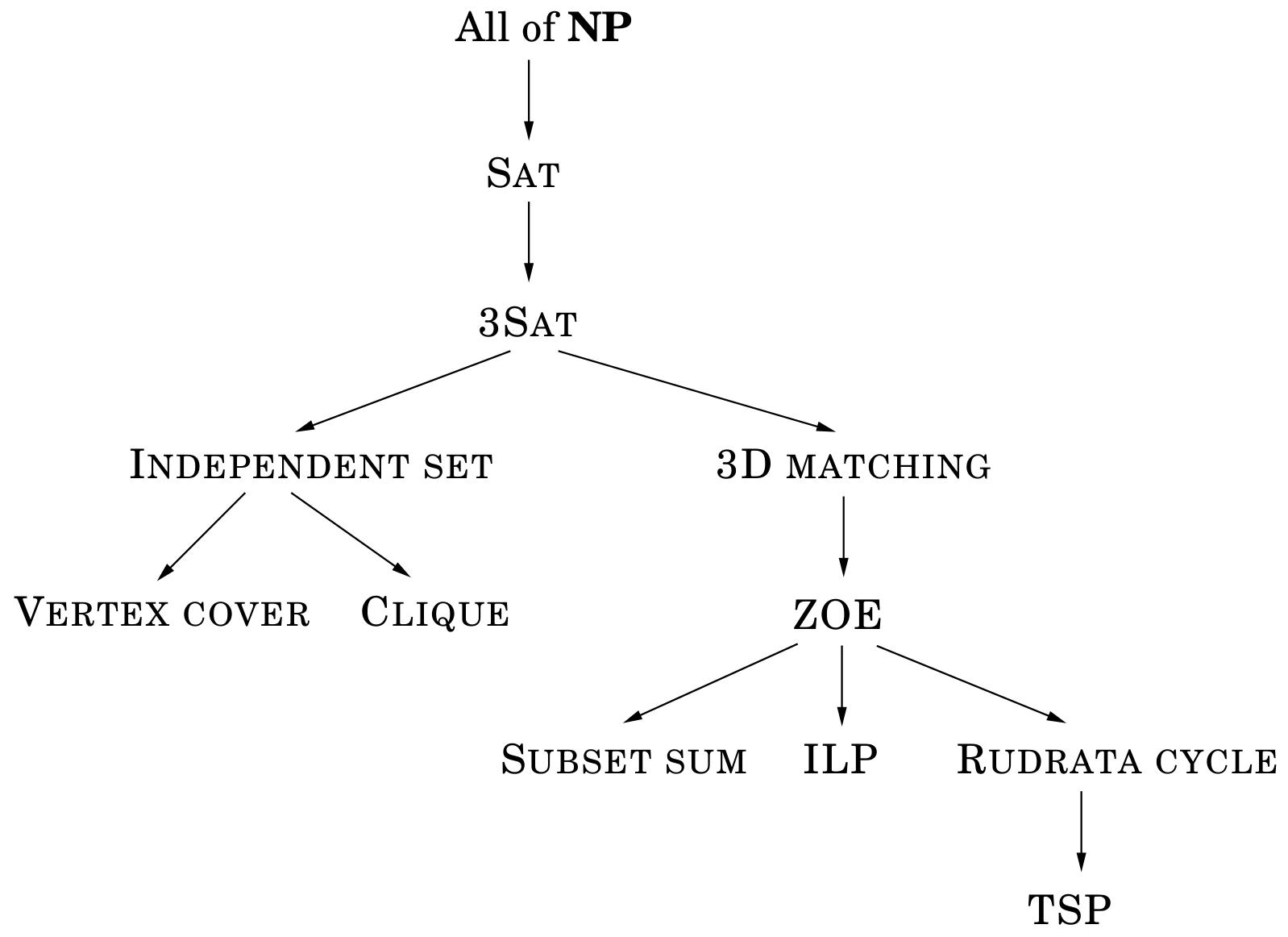
Reductions
A -> B (A不比B更难, A <= B)
要点:
- 实例转换
- 解转换(无解传递)
- 均在多项式时间内完成
对于非搜索问题,只需要进行实例转换。
规约链分析:3SAT → INDEPENDENT SET → VERTEX COVER → CLIQUE
1. 3SAT → INDEPENDENT SET(独立集)
- 目标:将布尔可满足性问题(3SAT)规约到独立集问题。
步骤:
a. 实例转换:- 对包含 k 个子句的 3SAT 公式,构造图 G:
- 每个子句对应一个三角形(3 个顶点),顶点表示子句中的文字(如 )。
- 添加冲突边:若文字互补(如 x 和
),则在所有三角形间连接它们。
- 设独立集目标大小 g = k(子句数)。
示例:公式
→ 两个三角形:
b. 解转换:
- 若存在大小为 g 的独立集,则每个三角形选且仅选一个顶点(无冲突边保证不选互补文字)。
- 令所选文字为 true(如选 x 则 x=true;选
则 x=false
- 对包含 k 个子句的 3SAT 公式,构造图 G:
- 核心洞察:
独立集选点 = 为每个子句选一个 true 文字,且全局赋值一致。
2. INDEPENDENT SET → VERTEX COVER(顶点覆盖)
- 目标:将独立集规约到顶点覆盖问题。
步骤:
a. 实例转换:- 给定图 G=(V,E) 和独立集目标 g,直接使用同一图 G
- 设顶点覆盖目标 b = |V| - g(如 |V|=5, g=2 → b=3
b. 解转换:
- 若存在大小 b 的顶点覆盖 C,则 是大小为 g 的独立集。
(因为 C 覆盖所有边 → 内无边) - 若存在大小 g 的独立集 S,则 是大小为 b 的顶点覆盖。
- 核心洞察:
独立集与顶点覆盖是互补问题:
3. VERTEX COVER → CLIQUE(团)
- 目标:将顶点覆盖规约到团问题。
步骤:
a. 实例转换:- 给定图 G=(V,E) 和顶点覆盖目标 b,构造其补图
- 设团目标 g = |V| - b(如 |V|=4, b=1 → g=3
b. 解转换:
- 若
存在大小为 g 的团 K,则 是 G 的大小为 b 的顶点覆盖。
(因 K 在中是完全图 → 在 G 中无边 → 覆盖 G所有边) - 若 G 存在大小 b 的顶点覆盖 C,则
是 的大小为 g 的团。
c. 无解传递:
- 若
无大小为 g 的团,则 G 无大小为 b 的顶点覆盖。
- 给定图 G=(V,E) 和顶点覆盖目标 b,构造其补图
核心洞察:
顶点覆盖的补集是补图中的团:

Other Algorithms
Euclid’s Algorithm
1 | Euclid(a, b) |
For any positive integers a and b ,the extended Euclid algorithm returns integers x , y ,and d such that go
RSA
1 | 1. 随机选择大素数 p, q → 计算 N = p * q |
RSA的正确性基于欧拉定理:
如果 gcd(m, n) = 1,则 m^φ(n) ≡ 1 (mod n)
Prime Testing
费马小定理: 如果 p 是素数且 a 是任意整数,则 a^(p-1) ≡ 1 (mod p)1
2
3
4
5
6
7primality2(N)
// Input: positive integer N
// Output: yes/no
1. Pick positive integers a1, a2, ..., ak<N at random
2. if ai^{N-1} ≡ 1 (mod N ) for all i=1,2, ..., k
then return yes
3. else return no.
Pr(primality2 returns yes when N is prime) = 1
Pr(primality2 returns yes when N is not prime) ≤ 1 / 2^k

