CS2314:智能语音技术的课堂笔记,由钱彦旻与俞凯老师主讲。
Lec1
傅里叶变换
公式:
傅里叶变换的性质:
- 线性:
- 时移:
- 频移:
周期信号与非周期信号的频谱特性:
- 周期信号的频谱是离散的,频谱中的频率成分都是基频的整数倍
非周期信号的频谱是连续的。
周期信号的频谱离散,谱线间隔
幅度按 或
变化.当 ,谱线包络过零 - 周期信号含有无穷多条谱线,但根据其包络,能量主要集中
在第一个零点内 (0 ∼),即低频信号能量大。
抽样信号
周期矩形脉冲的谱包络形状取决于矩形脉冲的宽度和周期。当矩形脉冲宽度为τ ,周期为T时,其频谱的包络线形状为抽样函数(Sa 函数)。
在周期矩形脉冲频谱中,
抽样定理
奈奎斯特采样频率指为使采样后的离散信号能精确重构原始连续信号,采样频率应达到的最低标准,需至少是原始连续信号最高频率的两倍。若原始信号最高频率为,则奈奎斯特采样频率表示为。
卷积定理
时域卷积定理:
频域卷积定理:
Lec2
拉普拉斯变换
为了解决傅里叶变换的局限性(满足迪利克雷绝对可积条件),拉普拉斯变换将信号分解为实部和虚部,从而可以处理非周期信号。
DTFT 离散时间傅里叶变换
离散时域,频域周期性。
DFT 离散傅里叶变换
| 时间 | 频率 |
|---|---|
| 连续 + 非周期 | 连续 + 非周期 |
| 连续 + 周期 | 离散 + 非周期 |
| 离散 + 非周期 | 连续 + 周期 |
| 离散 + 周期 | 离散 + 周期 |
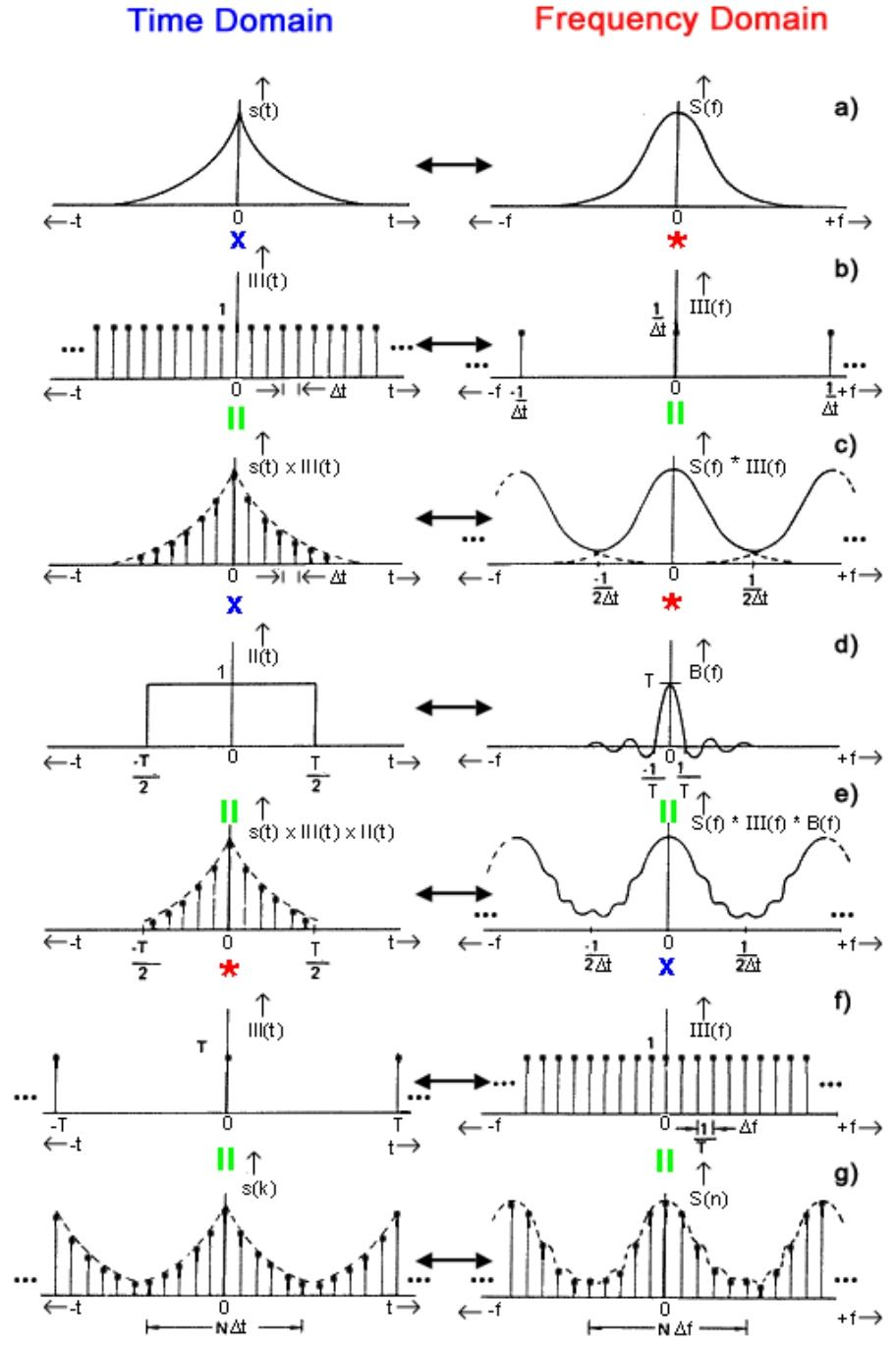
- 对称性
对于长度为N的离散信号进行 DFT 变换后,第k个频率分量的幅值与第
- 能量守恒定律(帕萨瓦尔定律Parseval Theorem)
窗函数
分帧处理:采用帧重叠部分表示语音的动态特性。
- 矩形窗
- 汉宁窗
- 汉明窗
- 布莱克曼窗
- 凯泽窗
选择:主瓣宽度影响频率分辨率,旁瓣衰减影响频谱泄露。
Lec3
浊音谱特征
共振峰结构:
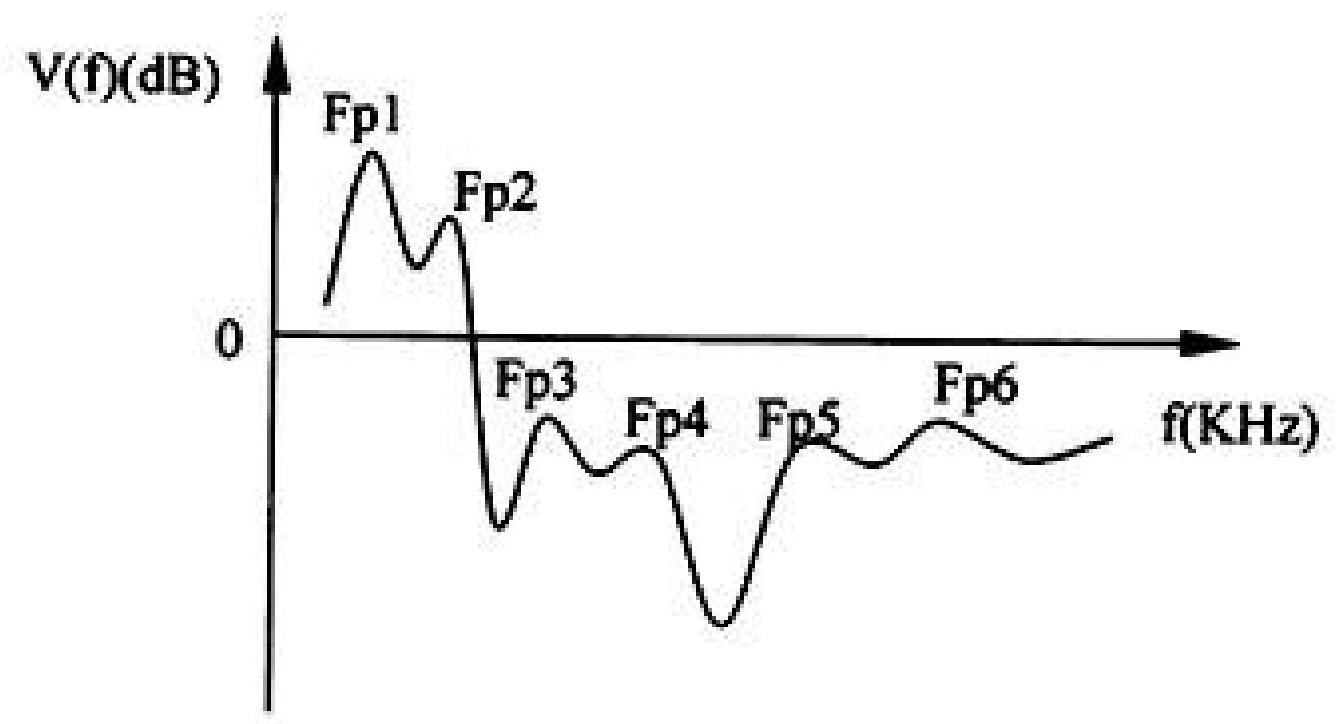
基音的检测
基音检测是语音信号处理中的关键环节,旨在获取声带振动的周期信息,为语音分析、合成和识别等任务提供基础支持。时域和频域都有多种基音检测方法,每种方法各有特点:
时域的基音检测方法
- AMDF法:定义平均幅度差函数$\gamma(l)=\sum{n = 0}^{N - l - 1}\left|S{w}(n + l)-S{w}(n)\right|
S{w}(n) l = nT n = 1, 2,\cdots T \gamma(l)$函数接近局部极小值。该方法仅用简单加减法运算,适用于早期普通CPU,因其乘法操作耗时较长。但在低信噪比环境下,抗干扰能力较弱,检测精度可能受影响。 - 自相关法:通过定义语音的自相关函数$R(l)=\sum{n = 0}^{N - l - 1} S{w}(n + l) S_{w}(n)
l = nT n = 1, 2,\cdots R(l)$函数接近局部极大值。数字信号处理器中有专门硬件指令能快速完成乘 - 累加操作,使该方法在DSP中应用广泛。不过,计算量相对较大,对硬件计算能力有一定要求。 - 中心削波法:先对语音信号进行中心削波,再计算自相关函数。利用自相关函数
的局部峰值点位置与语音幅度的峰值点位置重合这一特点,仅计算峰值点位置的自相关函数 ,然后搜索比较得到信号的基音周期。此方法可提高计算效率、减少干扰,但中心削波可能会损失部分语音信号细节信息。
- AMDF法:定义平均幅度差函数$\gamma(l)=\sum{n = 0}^{N - l - 1}\left|S{w}(n + l)-S{w}(n)\right|
- 频域的基音检测方法:主要采用谐波分析法,对浊音信号的谱线结构进行分析来计算基音周期。由于浊音信号具有与基音及其谐波相对应的谱线结构,通过分析这些谱线之间的关系,如频率间隔等,可确定基音周期。该方法对信号的频率成分分析较为准确,能有效利用频域信息。然而,频域变换计算量较大,且对信号的平稳性有一定要求,若语音信号存在突变或非平稳情况,检测精度可能下降。
听觉系统
1. 听觉感知特性
- 响度感知[Loudness Perception]
- 声压级SPL与响度关系:( L = k \log(P/P_0) )
- 应用:音频信号的动态范围压缩,响度均衡化
1 | def normalize_loudness(signal: np.ndarray) -> np.ndarray: |
- 频率分辨特性[Critical Band]
- 临界带宽:低频窄(~100Hz),高频宽(~500Hz)
- 应用:Mel频率尺度,用于提取MFCC特征
1
2
3def hz2mel(freq: float) -> float:
# Hz转Mel频率
return 2595 * np.log10(1 + freq/700)
2. 掩蔽效应应用
- 时域掩蔽[Temporal Masking]
- 前向掩蔽:~20ms
- 后向掩蔽:~200ms
- 应用:音频编码压缩,噪声抑制
- 频域掩蔽[Frequency Masking]
- 同时掩蔽:强信号掩盖临近频率的弱信号
- 应用:音频特征增强,语音增强
1
2
3
4
5
6def apply_frequency_masking(spectrum: np.ndarray) -> np.ndarray:
# 计算掩蔽阈值
masking_threshold = compute_masking_curve(spectrum)
# 低于阈值的频率分量被抑制
enhanced = np.maximum(spectrum - masking_threshold, 0)
return enhanced
3. 工程应用要点
- 语音特征提取
- MFCC特征:模拟人耳的频率响应
- PLP特征:整合等响度曲线
- Gammatone滤波器组:模拟基底膜响应
- 音频编码优化
- 基于掩蔽阈值的比特分配
- 动态范围压缩
- 声学回声消除
关键结论:
- 语音处理系统应当重点关注2kHz-5kHz频段(人耳最敏感区域)
- 临界带宽的非线性特性启发了Mel尺度的设计
- 掩蔽效应可用于音频压缩和降噪
这些听觉特性为语音信号处理提供了重要的理论基础和优化方向。
Lec5
高斯分布
- 表达式:一个均值为
、方差为 的高斯分布表达式为
均值
- 多变量高斯分布
- 形式:d维多变量高斯分布的形式为 。当协方差矩阵
为对角矩阵时,表达式可简化为 - 性质:以2维高斯分布为例,一个高斯的条件边缘概率、每一个分量的边缘分布、任意一个子集的联合边缘分布都是高斯分布;如果
服从高斯分布, ,那么 是一个均值为 $A\mu{x} + b A\sum{x}A^{\top}$ 的高斯分布。
- 形式:d维多变量高斯分布的形式为 。当协方差矩阵
- 期望和方差:对于多变量高斯分布
,通过积分运算可以得出其期望 , ,协方差 。 - 对高斯分布而言,独立等价于不相关
Lec8
前端处理:语音端点检测(VAD)
传统的有监督 VAD 模型训练流程
▶ 1. 采集干净的单人语音数据,尤其是音频质量相差不大的
数据。确保数据中仅包含固定种类的一种/多种语言。
▶ 2. 手动对这些数据进行文本标注。
▶ 3. 在这些数据上训练一个 ASR 模型。
▶ 4. 用训练好的 ASR 模型来预测新的(通常干净)数据集中
的音频是否存在语音,以得到帧级别的强标注。
▶ ASR 模型可以提供音素级别的对齐,进而转换为二值的语音
指示(有语音的帧设为 1,静音段设为 0)
▶ 5. 在新数据集上用前一步得到的强标注训练一个 VAD 模型
(DNN/CNN/RNN 等)。
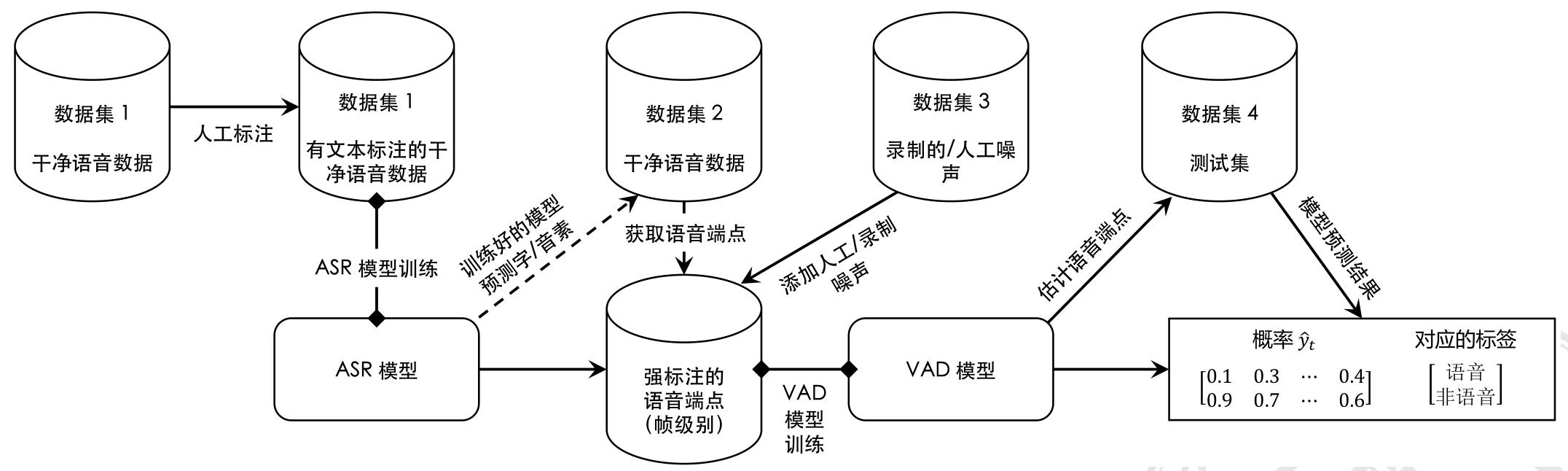
性能评估指标
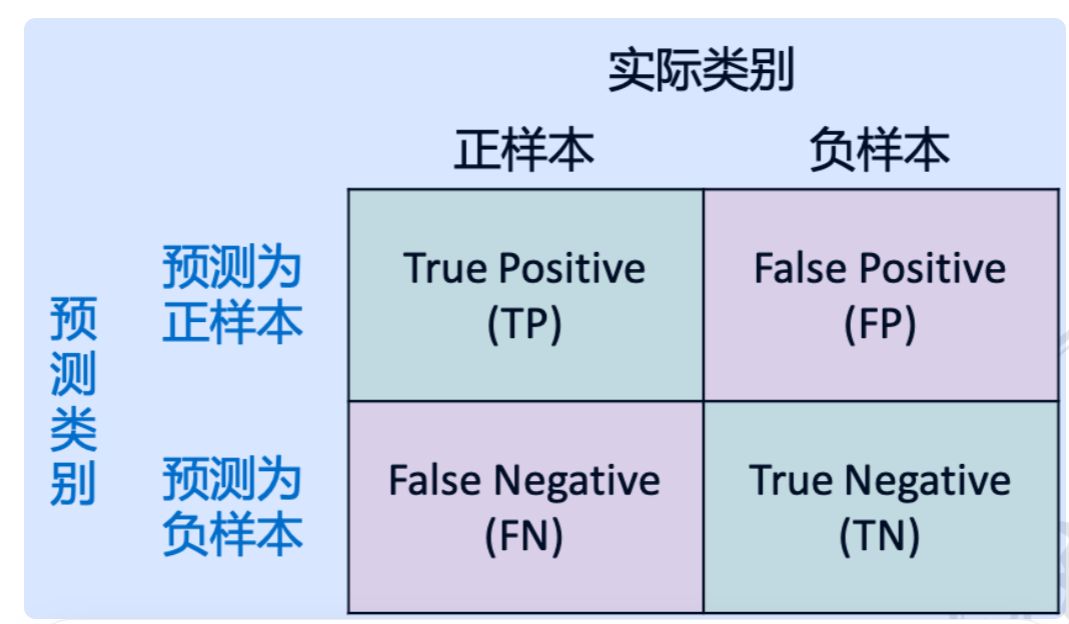
- 准确率:在所有样本中,预测正确的正样本和负样本所占比例
问题:在实际的语音检测场景中,语音和非语音的分布往往不均衡。可能大部分音频数据是非语音部分,故若全判为非语音部分准确率仍然很高。
启示:这是一个检测问题而非二分类问题
召回率/查全率(Recall)/TPR (True Positive Rate):在所有正样 本中,被预测正确的比例
值:精确率和召回率的(加权)调和均值 其中 β 的取值可根据精准率和召回率在评估时的相对重要 性来决定,通常取1:
宏平均F1 值(macro-averaging F1 score)
微平均F1 值(micro-averaging F1 score)
宏平均为算术平均,受极值影响大;微平均为调和平均,对数据分布更加敏感
ROC 曲线(Receiver Operating Characteristic curve):在不同阈值 下,TPR (True Positive Rate) 和FPR (False Positive Rate) 组成 的曲线 TPR = TP TP + FN TNR = TN TN + FP,
AUC (Area Under Curve):ROC 曲线下的面积
Lec12
n-gram语言模型
n-gram语言模型是一种基于统计的自然语言处理模型,用于预测文本序列的概率。它通过计算词语序列的联合概率来建模语言规律,是早期语言模型的核心方法之一。以下是其核心概念和应用解析:
1. 基本概念
- n-gram:由连续的 n 个词组成的子序列。
- Unigram (1-gram):单个词(如“模型”)。
- Bigram (2-gram):相邻两个词(如“语言模型”)。
- Trigram (3-gram):相邻三个词(如“自然语言处理”)。
- 马尔可夫假设:假设当前词的概率仅依赖前 n-1 个词,而非整个历史。例如:
- Bigram模型:
- Trigram模型:
2. 概率计算
通过最大似然估计(MLE)从语料库中统计频次:
- 示例:Bigram模型下,
假设语料库中:
- “I love” 出现100次,“I love NLP” 出现30次,
- 则 ( P(\text{NLP} | \text{love}) = \frac{30}{100} = 0.3 )。
生成文本时,可基于概率选择下一个词(如“NLP”)。
分支度
- 分支度:表示在给定前 n-1 个词的条件下,当前词的可能取值数量。分支度越高,模型越复杂。
- 计算:
- 示例:在“我爱自然语言处理”中,“我”后面可能跟“爱”、“喜欢”等,分支度较高;而“我”后面只能跟“爱”,分支度较低。
perplexity
- 定义:Perplexity 是语言模型的评估指标,表示模型对测试集的困惑程度。值越低,模型越好。
- 计算:
- 示例:假设模型对句子“我爱自然语言处理”的概率为0.01,句子长度为5,则 perplexity 为
- perplexity可能为无穷大,因为在稀疏数据中,某些n-gram可能在训练集中未出现,导致概率为0。

