记录CS61C课程的学习过程,跟随CS61C: Computer Architecture(Machine Structures)25春季版本。
本文包含课程的Introduction和C语言基础。Lecture 1-7, Discussion 1-2。
Thinking about Machine Structures
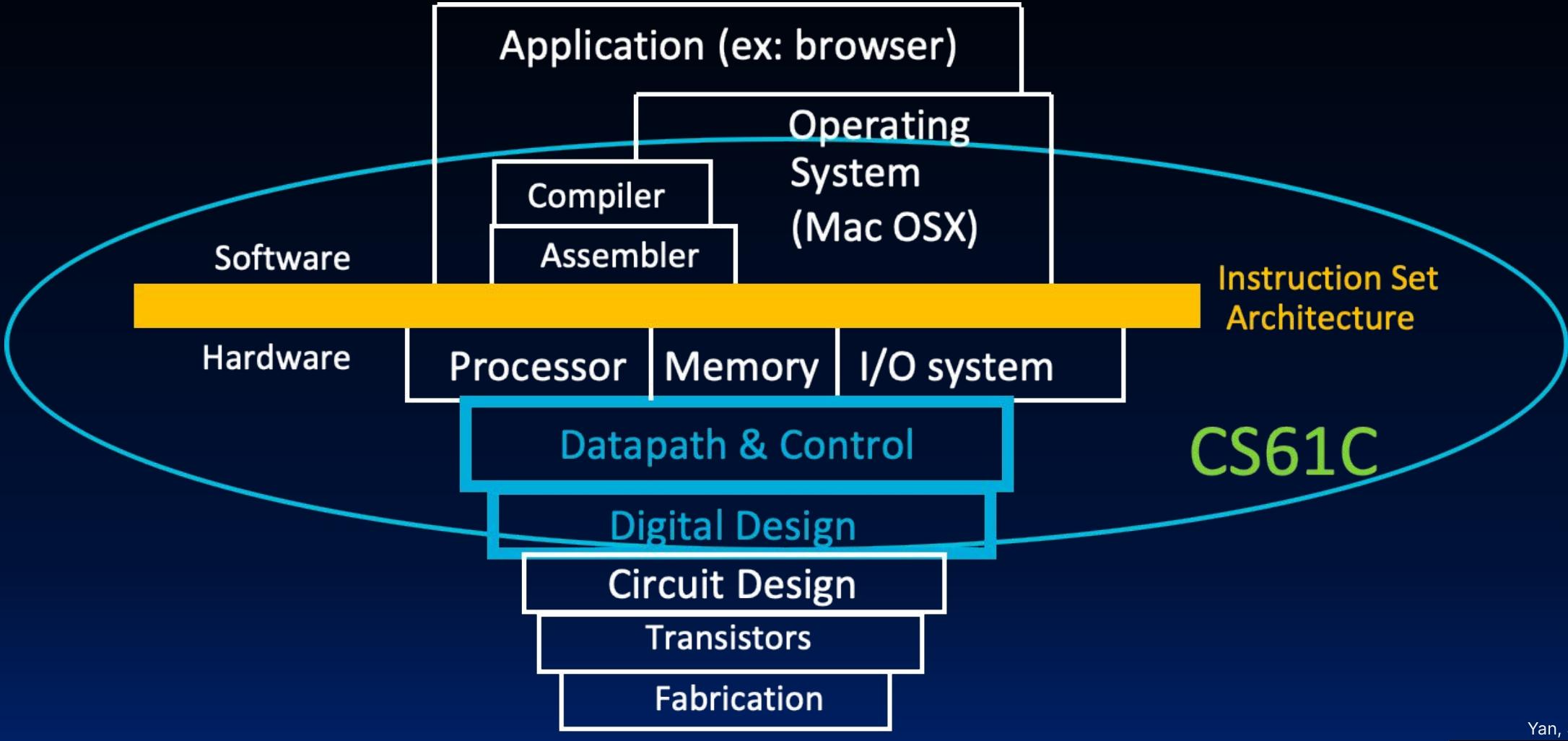
Great Ideas in Computer Architecture
- Abstraction (Layers of Representation/Interpretation)
- Mooreʼs Law
- Principle of Locality/Memory Hierarchy
- Parallelism
- Performance Measurement & Improvement
- Dependability via Redundancy
Number representation
Bias Encoding
假设我们有一个数据值 x,存储时的计算方式为:存储值 = x - bias(将结果作为无符号数存储);读取时的计算方式为:实际值 = (存储的无符号数) + bias。
在 N 位表示中,偏移量通常选为
举例:N = 4, bias = -7
对0,存储值为:
读取时,实际值为:
Intro to C
由于笔者有丰富的c++开发经验,故着重介绍c语言与c++的区别。
Compile
1 | gcc hello.c -o hello |
头文件:#include <stdio.h>
printf 和 scanf 函数
参数:
%d:整数%f:浮点数%c:字符%s:字符串%p:指针%u:无符号整数%g:自动选择合适的表示方式
scanf 函数需要取地址符&,因为 scanf 函数需要将输入的值存储到变量中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
int main() {
int a;
float b;
char c;
char str[100];
// 输入整数
printf("请输入一个整数: ");
scanf("%d", &a);
// 输入浮点数
printf("请输入一个浮点数: ");
scanf("%f", &b);
// 输入字符
printf("请输入一个字符: ");
scanf(" %c", &c); // 注意前面的空格,跳过前面的空白字符
// 输入字符串
printf("请输入一个字符串: ");
scanf("%s", str); // 不需要取地址符,因为数组名即为地址
// 输出结果
printf("您输入的整数是: %d\n", a);
printf("您输入的浮点数是: %.2f\n", b);
printf("您输入的字符是: %c\n", c);
printf("您输入的字符串是: %s\n", str);
return 0;
}
字符串处理
<string.h> 是C语言标准库中的一个头文件,它提供了一系列用于处理字符串的函数。以下是一些常用函数的详细介绍:
strlen:计算字符串长度strcpy:复制字符串strcat:连接字符串strcmp:比较字符串strchr:查找字符strstr:查找子字符串strncpy:复制指定长度的字符串
1 |
|
results:1
2
3
4
5字符串长度: 13
复制后的字符串: Hello, World!
连接后的字符串: Hello, World! Welcome!
两个字符串相等
字符 o 的位置: 4
爆典:”C gives you a lot of extra rope, donʼt hang yourself with it!ˮ
malloc, free and realloc
1 |
|
K&R Malloc/Free Implementation
- 内存块结构:每个内存块前都有一个头部,头部包含两个字段。一个是表示该内存块大小的字段,用于记录当前内存块包含的字节数;另一个是指向下一个内存块的指针。在已分配的内存块中,指针字段未被使用;而所有空闲的内存块通过这个指针字段连接起来,形成一个循环链表,方便内存管理。
- malloc()函数实现:
malloc()函数用于从堆中分配内存。它会在空闲链表中搜索,寻找一个大小足够满足请求的内存块。若找到合适的块,就将其从空闲链表中移除,并根据需要对该块进行分割(如果请求的内存小于找到的块的大小),然后返回指向分配内存起始位置的指针。如果在空闲链表中找不到足够大的块,malloc()会向操作系统请求更多内存。若操作系统提供的内存仍无法满足请求,malloc()函数则返回NULL,表示内存分配失败。 - free()函数实现:
free()函数用于释放不再使用的堆内存。当调用free()时,它首先检查要释放的内存块的相邻内存块是否也处于空闲状态。如果相邻块空闲,free()会将这些相邻的空闲块合并成一个更大的空闲块,以减少内存碎片,提高内存利用率。若相邻块都在使用中,就直接将当前释放的内存块添加到空闲链表中。这样,后续调用malloc()时,该内存块可再次被分配使用。 - 设计目标:K&R实现方式的主要目标是使
malloc()和free()能够高效运行,同时尽量减少内存开销,并避免内存碎片化问题。碎片化指的是虽然系统中有许多空闲内存,但由于这些空闲内存以许多小的不连续块存在,导致无法满足大的内存分配请求。K&R实现方式通过合理的内存块管理和合并策略,在一定程度上缓解了这些问题,为C程序提供了较为有效的内存管理方案。
Function Pointers
1 |
|
Generic Functions 泛型函数
通用指针(void *)不能使用解引用操作符,因为解引用指针需要在编译时确定访问字节数。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// 泛型swap函数:交换任意类型的两个元素
void swap(void *a, void *b, size_t size)
{
char temp[size]; // 创建临时缓冲区
memcpy(temp, a, size); // 将a的内容复制到临时缓冲区
memcpy(a, b, size); // 将b的内容复制到a
memcpy(b, temp, size); // 将临时缓冲区的内容复制到b
}
int main() {
// 交换整数
int x = 5, y = 10;
printf("交换前: x = %d, y = %d\n", x, y);
swap(&x, &y, sizeof(int));
printf("交换后: x = %d, y = %d\n", x, y);
// 交换浮点数
double d1 = 3.14, d2 = 2.718;
printf("交换前: d1 = %f, d2 = %f\n", d1, d2);
swap(&d1, &d2, sizeof(double));
printf("交换后: d1 = %f, d2 = %f\n", d1, d2);
return 0;
}
为实现泛型中的指针运算,需先把void *指针强制转换为char *指针。因为char类型在任何架构下都占 1 字节,转换后指针运算就以字节为单位,保证运算按字节进行。
示例:
在swap_ends函数中交换通用数组首尾元素,计算末尾元素地址时,先将指向数组起始地址的void *指针arr转换为char *,再按公式(char * ) arr + (nelems - 1)* nbytes计算,nelems是数组元素个数,nbytes是每个元素的字节大小。
Floating Point Representation
数字表示法回顾
计算机以二进制表示数字,N位可表示个不同值。无符号整数范围是0到 ,有符号整数(补码表示)范围是 。
定点数表示法
定点数是一种将小数点位置固定的数字表示方法。通过预先确定二进制小数点的位置,可以表示整数和分数部分。
例如,在8位定点表示中,如果我们规定前4位表示整数部分,后4位表示小数部分:
- 数字 5.5 表示为:0101.1000
- 整数部分 5 = 0101₂
- 小数部分 0.5 = 0.5 × 2⁴ = 8 = 1000₂
- 数字 3.25 表示为:0011.0100
- 整数部分 3 = 0011₂
- 小数部分 0.25 = 0.25 × 2⁴ = 4 = 0100₂
定点数的优点是运算简单,但缺点是表示范围有限:
- 在上述8位系统中,整数部分范围为0-15
- 小数部分精度固定为1/16 (0.0625)
浮点数表示法
浮点数通过分离二进制点和有效位,能有效利用有限位表示更多数。IEEE 754标准规定单精度浮点数为32位,包括1位符号位、8位指数位和23位有效数位。其中,有效位隐式包含首位1,指数采用127的偏移表示法。

- 浮点数运算特性:浮点数加法不满足结合律,如不同运算顺序结果可能不同,这是因为浮点数表示是近似的,且大指数对应较大步长。浮点数运算涉及舍入操作,IEEE 754有多种舍入模式 ,如向+∞、-∞舍入,截断,向偶数舍入等。
- 特殊浮点数:特殊浮点数包括零(±0)、无穷(±∞)、非数(NaN)等。指数为0且有效位全0表示±0;指数为0且有效位非0表示非规格化数;指数为255且有效位全0表示±∞;指数为255且有效位非0表示NaN ,用于处理溢出、下溢、非法运算等情况。
- 不同精度浮点数:双精度浮点数(64位)相比单精度,指数偏移为1023,能表示范围更广、精度更高的数。此外,还有半精度(16位)、四精度(128位)等多种浮点数格式,各有不同的应用场景,如半精度在机器学习中用于加速计算。

